The evolving technology is highly dependent on the simplification of task today. Many aids and tools are defined to reduce human effort and intervention. Image processing is one of the emerging topics in the current era. Other than its use in medical industry, it has been playing a vital role in other fields of deep analysis and search which are popular in navigation, telecommunication, education and what not. However, image processing has brought in lime light the wonders of neural networks, whether be it artificial or conventional.
Neural network is an algorithm which makes it way in classification and image analysis tasks. Machine learning remains incomplete without the implementation of neural networks due to its excellent capacity in subsequent data analysis techniques, most preferably, Natural Language Processing. In this every data scientist’s go to classification algorithm as it requires much less processing and can perform better while training data.
ARCHITECTURE:
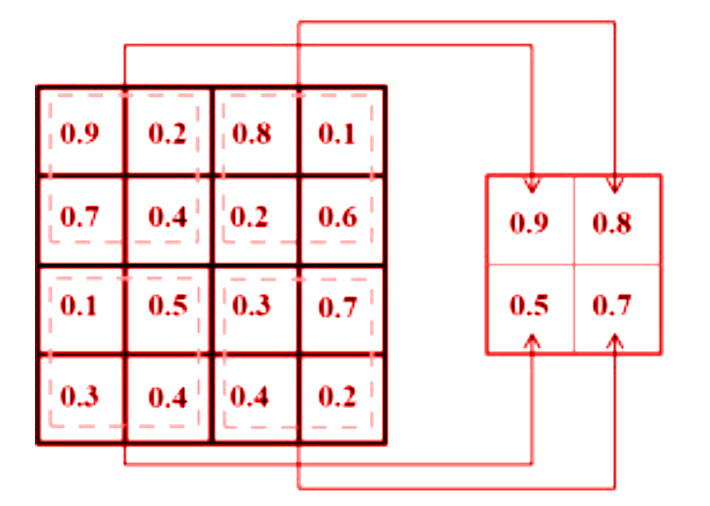
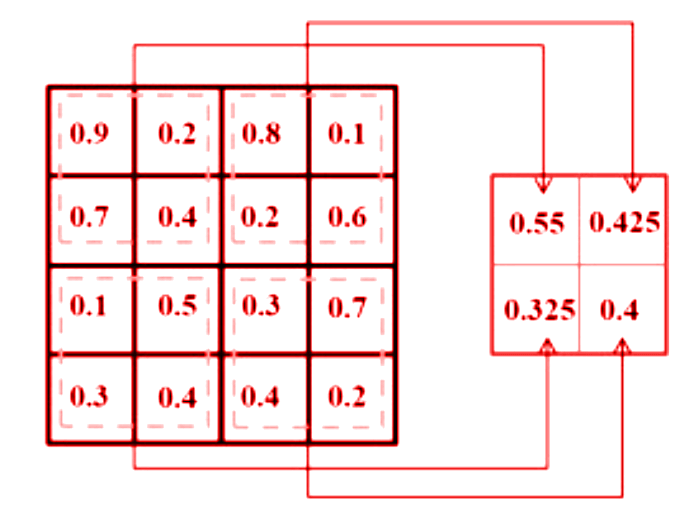
The framework of neural networks is much tideous to observe and understand. The architecture of neural networks works in layers. Commonly, a neural network consists of an input layer, an output layer and multiple hidden layers. The hidden layers are not literally hidden but its implementation is kept abstract from the user. It may include convolution layers, ReLU layers, pooling layers, fully connected layers, and normalization layers.
CONVOLUTION LAYER:
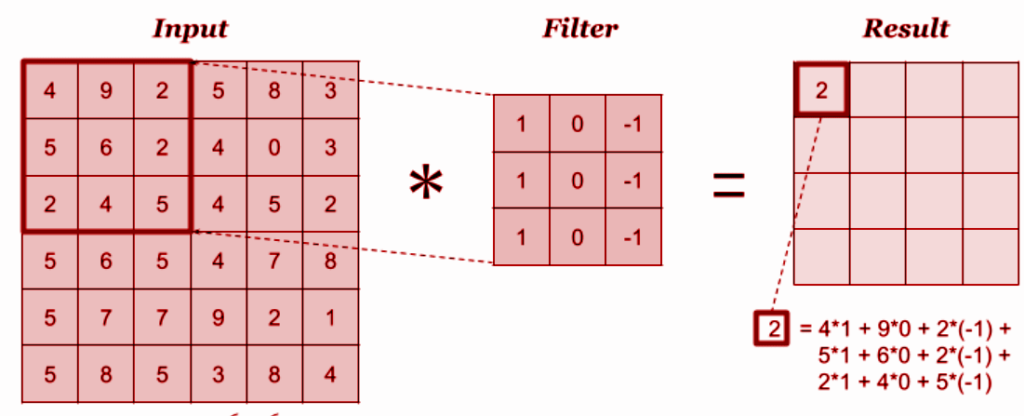
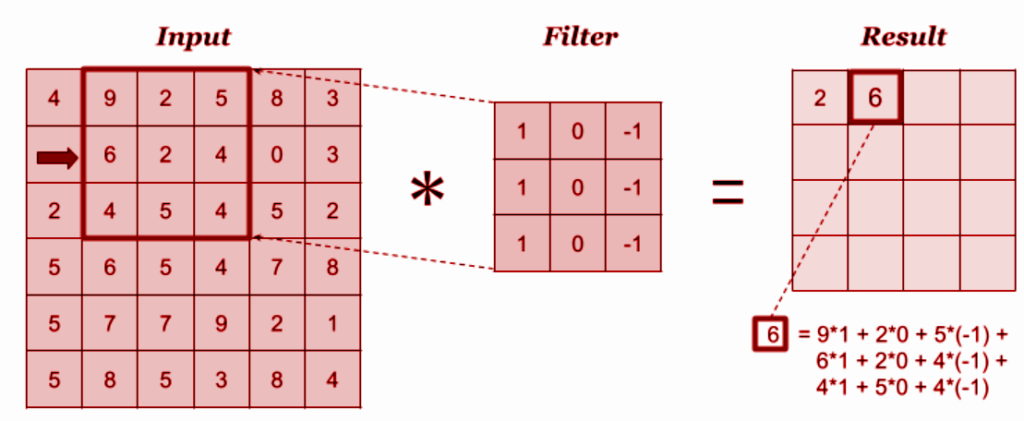
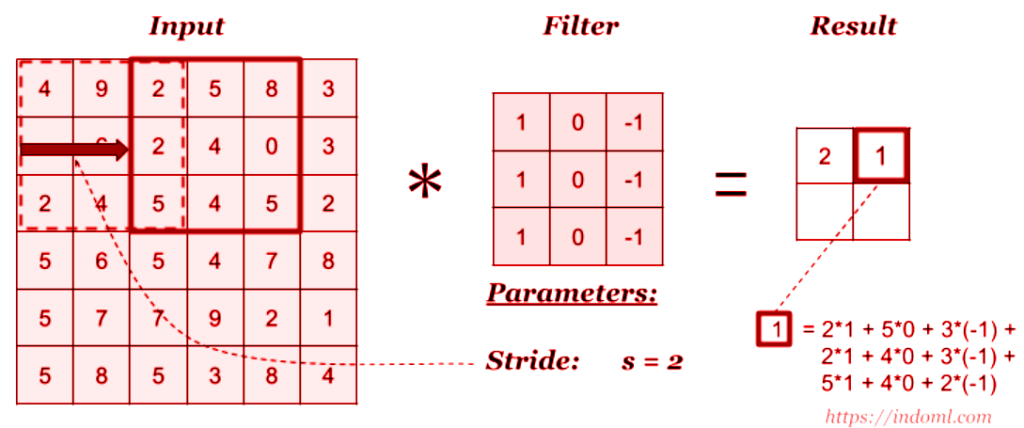
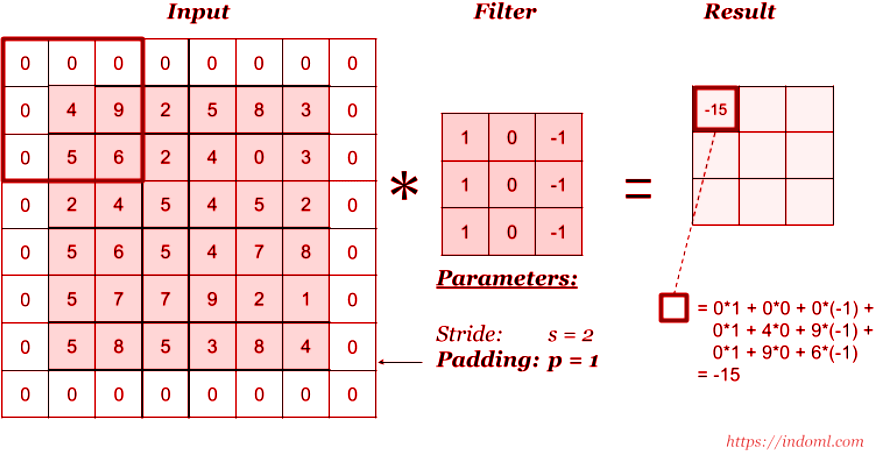
The convolution layer is the layer where one can perform mix and match or experiment with elements in the image. It uses filters to obtain different features of the image that makes sense so that meaningful results and observations can be drawn out from it.
The principle rule of working with convolution layers is figuring out which filters to be applied. Filters are nothing but matrices designed in such a way that a particular output is achieved.
A given image is first passed through numerous filters coded as per requirement. The outcome includes kernel which are distinct in feature maps. Filtering works by overlaying the filter on the input section, the filters are element-wise multiplied and elements are added.